The ISP Column
A column on things Internet
| |
Other Formats:
| |
More Leaky Routes
June 2015
Geoff Huston
Most of the time, mostly everywhere, most of the Internet appears to work just fine. Indeed, it seems to work just fine enough to the point that that when it goes wrong in a significant way then it seems to be fodder for headlines in the industry press.
This time the problem started in Malaysia and its major Internet service provider in the country, Telekom Malaysia, on the 12th June. In looking at what happened and why it is perhaps useful to start with a brief recap on how the Internet knows where everything is. So time for a brief digression into the routing system.
Interconnection and Routing in the Internet – a quick tutorial
When any two networks interconnect, then the way in which they learn about each other’s networks is via an exchange of routing information. A network in this case can be though of as a collection of reachable IP addresses (routes), and the connection of two networks implements a simple form of "I'll tell you my routes and you tell me yours."
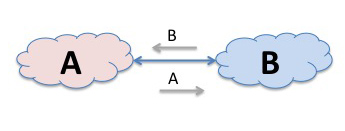
Let's use two networks, and call them A and B. And lets assume that the networks A and B have interconnected in this manner. So now if a source in A's network wants to send a packet to a destination in B's network, then, as A and B are directly connected, A has learned all about the set of IP addresses that are reachable in B's network so A's routing system will direct the packet to B’S network.
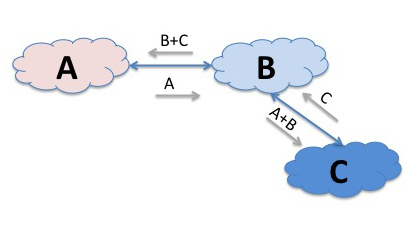
Now lets add a third element to this model. What if we have a third network C, that connected to B? If B was prepared to act as a "transit" service provider then B could announce C's routes to A in addition to its own routes, and announce A's route's to C. Now all points in these three networks can reach each other. If a source in A sends a packet to a destination in C, then A's routing system will direct the packet to network B, as A learned C’s routes via network B. B's routing system will recognise the destination address as one located in network C, and will pass it across to C.
Conventionally, we call the networks A, B and C Autonomous Systems, and the routing protocol used to exchange routes on the Internet is the Border Gateway Protocol, or BGP. And if you repeat and rinse the above interconnection scenario another 50,000 times to accommodate the interconnection of 50,000 networks, and use BGP to exchange route information for some 560,000 routes then you end up with something that is much the same scale as today's Internet.
There are many ways one could interconnect 50,000 ASs using the basic tool of pairwise connection. We could use linear connectivity, rings, hub and spoke, or any form of connection topology. One visualisation of the interconnection of the Internet is as shown below:
What shapes the Internet's particular configuration? The best answer I can offer is that the Internet is shaped a combination of money and geography. Geography is the tendency for networks to interconnect to other networks that are physically close. There is a significant industry devoted to running so-called "exchange points" all over the world, which is a dedicated facility where local networks can drop a connection and use the exchange point's switching equipment to interconnect with all the other networks who also present themselves at this point. The motivations for geographic proximity rest in performance and, of course, money. If two networks have an interconnection path that spans the world then the time taken for a packet to traverse this extended path will be far slower than it takes for a packet to traverse a path that spans a metro area or a continental domain. So closer connectivity creates a superior user experience. And, while its not universally true, its certainly more common than not, that longer paths, particularly those that span one or more oceans, cost more per packet than shorter paths. So, in general, shorter network paths are cheaper.
Money is the major motivator for interconnection, as, ultimately its money that drives this industry. To illustrate this lets go back to our simple A, B, and C network example. When C connects to B, what would motivate B to announce C's networks across to A? Don't forget that in doing this the traffic flowing between A and C will consume B's network resources, but B does not have a direct relationship with either of the end users who are generating this traffic flow. So B cannot bill either A or C's customer to compensate it for providing this service. One viable solution here is for C to pay B for this transit service. In effect, B is C's provider, or, viewed from the other side, C is B's customer. In theory it might be possible to organise the world of interconnected networks into a connectivity mesh using only customer-provider relationships, but at times it might get tricky. To illustrate this, lets add a another network to our example, network D, who is a customer of A. Now when D exchanges traffic with C then D will pay A and C will pay B, as we would expect for customer provider relationships. But what about the relationship between A and B? Sometimes, when A and B are a similar size and scale it is not easy to naturally define who is the provider and who is the customer. The ISP industry has devised an additional form of relationship to address precisely this situation, which is the "peer" relationship, where the two networks interconnect, but agree not to invoice each other (this was the old SKA, or Sender Keep All arrangement).
So we have three roles for a network in the domain of interconnection: customer, provider and peer, and many networks have all three relationships at once. Bearing in mind that a network generates revenue from its customers, spends money on its providers and is revenue neutral with its peers, then its clear that providers would like to maximise preference with its customers over peers and providers, and prefer peers over providers. that way a provider can maximise revenue and minimize expenditure.
The way this is implemented in a network's routers is by using local preference settings in BGP. It all external connections are categorised simply into one of these three categories, then the local preference setting can be used to prefer customer-announced routes over peer-announced routes over provider-announced routes. So if a network sees the same route being advertised from a customer and from a peer or a provider, the local preference setting is intended to ensure that the network will prefer the path via the customer over the path via the peer.
These local preference settings have a high precedence in the BGP decision-making algorithm, and local preference overrides the default BGP comparison algorithm that compares AS path length. So even if a network uses AS path prepending to attempt to bias the path selection, the local preference setting will override this.
It's also helpful to understand re-advertisement preferences in a network, as this too is part of the process of a network attempting to optimise its position by maximising revenue and minimising expenses, and stopping "free riding" where the network is used by unfunded traffic.
To do this most network used the following basic redistribution rules:
- customer-learned routes are re-distributed to customers, peers, and providers
- peer-learned routes are re-distributed to customers but not to other peers nor to providers
- provider-learned routes are re-distributed to customers, but not to other providers, nor to any peers.

http://www.opte.org
What Happened?
Now let’s go back to the 12th June and look at what happened. Certainly something happened, as can be seen in the following two figures. The first is an hour-by-hour plot of the total number of prefixes announced in the Internet’s routing table.
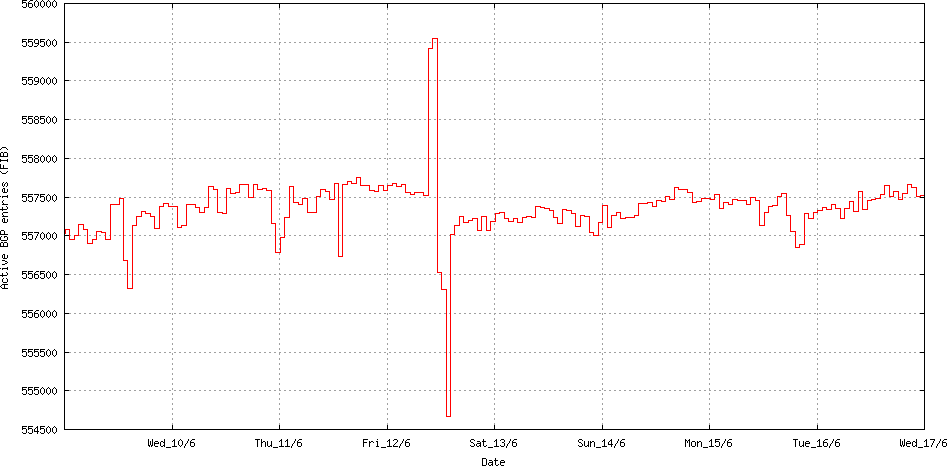
Routing Table Size: Week starting 9th June 2015 (www.potaroo.net)
It looks as if 2,500 additional routes were added to the routing system, and then a couple of hours later some 5,500 routes were withdrawn, followed by the restoration of 2,500 routes, leaving the routing system some 500 routers smaller than the original state.
A similar picture is evident when looking at the updates in BGP across the same period, where the change in the BGP table size was matched by a corresponding burst in BGP update activity.
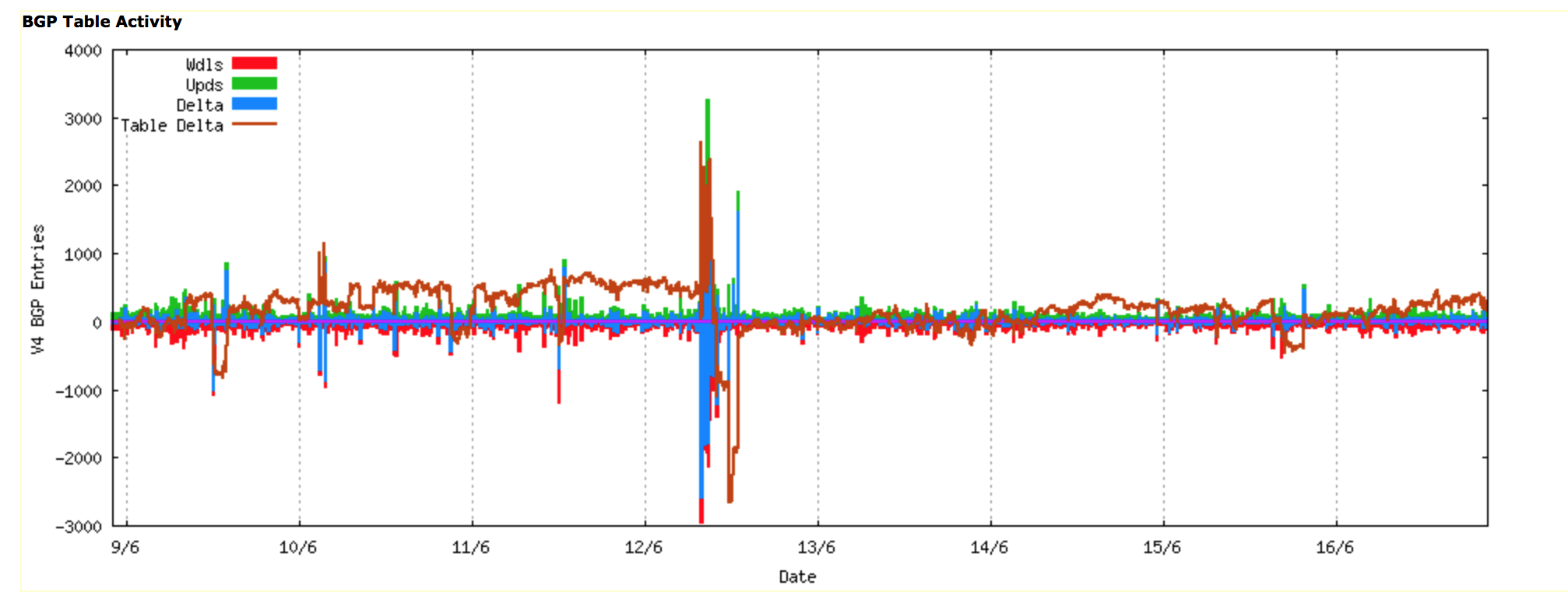
Routing Update Activity: Week starting 9th June 2015 (www.potaroo.net)
This burst of activity originated at AS4788, the network operated by Telekom Malaysia.
Telekom Malaysia is a relatively large provider in Malaysia. It's customer base has in the region of 15 million users from its own network, and it provides transit services to 64 other networks, mostly based in SE Asia. This network also appears to have 13 upstream providers. The upstream providers, and the number of prefixes seen via each provider from a vantage point located in Australia at AS131072 is as follows:
| AS3320 | DTAG Deutsche Telekom AG, DE (7 prefixes) |
| AS3356 | LEVEL3 - Level 3 Communications, Inc., US (1 prefix) |
| AS4637 | ASN-TELSTRA-GLOBAL Telstra Global, HK (1,131 prefixes) |
| AS9304 | HUTCHISON-AS-AP Hutchison Global Communications, HK (1 prefix) |
| AS24115 | ASN-EQIX-MLPE Equinix, HK (1,296 prefixes) |
| AS6453 | TATA COMMUNICATIONS (AMERICA) INC, US (2 prefixes) |
| AS2516 | KDDI KDDI CORPORATION, JP (2,074 prefixes) |
| AS18206 | VPIS-AP VADS Managed Business Internet Service Provider, MY (1 prefix *) |
| AS1273 | CW Cable and Wireless Worldwide plc, GB (183 prefixes) |
| AS3257 | TINET-BACKBONE Tinet SpA, DE (179 prefixes) |
| AS1299 | TELIANET TeliaSonera AB, SE (3 prefixes) |
| AS6939 | HURRICANE - Hurricane Electric, Inc., US (2,222 prefixes) |
| AS17557 | PKTELECOM-AS-PK Pakistan Telecommunication Company Limited, PK (15 prefixes) |
* this appears to be some form of routing error
Like many ISPs with a large set of upstream providers Telekom Malaysia use the technique of the announcements of more specifics to manage their traffic loads over various physical circuits. In this case Telekom Malaysia has taken the 56 IPv4 address blocks that it has been allocated from its local Regional Internet Registry and they advertise some 2,200 distinct prefixes, mostly using /24 more specific advertisements drawn from the covering aggregate address blocks. The generation of 1,144 more specifics places Telekom Malaysia as one of the larger generators of more specifics in today’s Internet, but by no means the largest. This approach is performing traffic engineering over diverse physical connections by selective announcements of more specific address prefixes may be commonplace, but it can still be complicated. And of course complicated approaches often turn into operationally fragile arrangements that are prone to mishaps.
And that’s what appeared to happen to Telekom Malaysia on the 12th of June.
What the rest of the world saw was a surge of route advertisements coming out of AS4788, including some 2,500 new prefixes that had not been seen before. A couple of hours later there was a large scale withdrawal of some 5,500 prefixes, before stabilizing back with the re-advertisement of some 2,500 prefixes, as shown above.
If we look at just AS4788, and look at updates coming from that AS, we can break them down into prefixes that are originated by AS4788 and prefixes where AS4788 is a transit provider. The log of origin and transit activity for AS4788 over the 12th June shows a rapid rise in activity at 0843 on that day, lasting for 9 minutes.
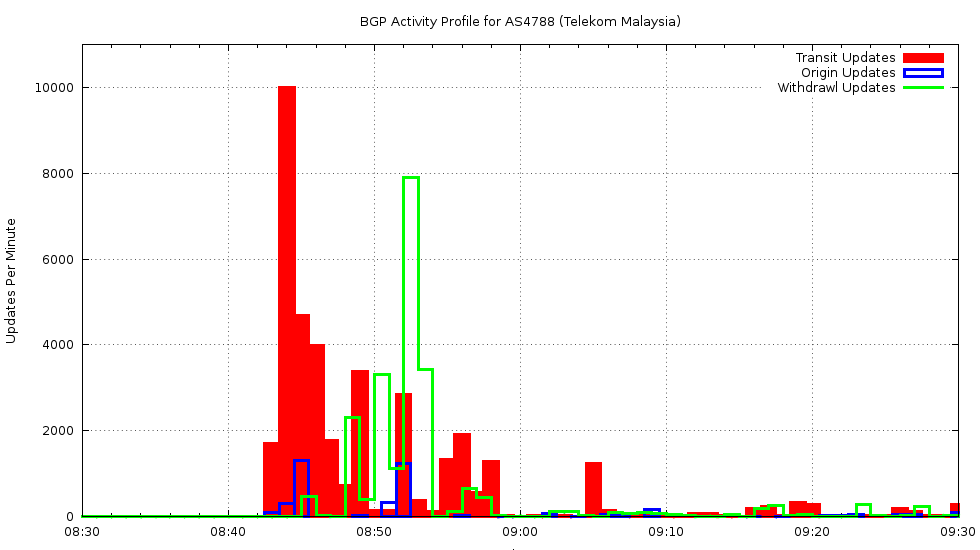
Routing Update Activity: AS4788 0830 – 0930 12th June
Most of this route update activity came in the form of the announcement of routes where AS4788 was a transit AS, rather than the origination of new routes originating in AS4788.
So what happened? There are two major forms of route leak: one is where a network imports eBGP-learned routes in one part of its network and converts internal routes to eBGP-exported routes in another part of its network. The routes that are mistakenly handled in this fashion appear to other networks as if they originated in this network. The other form is where eBGP-learned routes from one peer network are mistakenly exported to another peer network. In this case the external view is that the leaked routes include this network as a “transit”.
In the case of this particular route leak we saw a transit route leak, where AS4788 was re-advertising routes learned from one routing peer to another peer.
Which routes where affected? A list of 22,577 routes is probably too much for here, but lets look at the set of neighbour ASs whose routes appeared to be re-advertised by AS4877 over this period. Here’s the top 20, as seen from a BGP vantage point located in AS4777 Japan.
| Prefixes | ASN | Description |
|---|---|---|
| 5,545 | 6695 | DECIX-AS DE-CIX Management GmbH, DE |
| 3,699 | 9394 | CTTNET China TieTong Telecommunications Corporation, CN |
| 3,381 | 1273 | CW Cable and Wireless Worldwide plc, GB |
| 1,594 | 4788 | TMNET-AS-AP TM Net, Internet Service Provider, MY (Announced Prefixes) |
| 818 | 8359 | MTS MTS OJSC, RU |
| 781 | 38285 | M2TELECOMMUNICATIONS-AU M2 Telecommunications Group Ltd, AU |
| 643 | 2119 | TELENOR-NEXTEL Telenor Norge AS, NO |
| 561 | 3209 | VODANET Vodafone GmbH, DE |
| 422 | 8708 | RCS-RDS RCS & RDS SA, RO |
| 365 | 17557 | PKTELECOM-AS-PK Pakistan Telecommunication Company Limited, PK |
| 260 | 16150 | PORT80-GLOBALTRANSIT Availo Networks AB, SE |
| 242 | 12552 | IPO-EU IP-Only Networks AB, SE |
| 241 | 23520 | COLUMBUS-NETWORKS - Columbus Networks USA, Inc., US |
| 220 | 3741 | IS, ZA |
| 186 | 4635 | HKIX-RS1 Hong Kong Internet Exchange--Route Server 1, HK |
| 162 | 41095 | IPTP IPTP LTD, NL |
| 153 | 5588 | GTSCE T-Mobile Czech Republic a.s., CZ |
| 147 | 2647 | SITA Societe Internationale de Telecommunications Aeronautiques, FR |
| 144 | 8426 | CLARANET-AS ClaraNET LTD, GB |
| 143 | 2686 | ATGS-MMD-AS - AT&T Global Network Services, LLC, US |
This list is quite different from the list of upstream transit ASs above. The likely reason is that AS4788 is present at a number of exchange points, and is picking up a large number of routes from these exchange points. During this route incident AS4788 re-advertised these learned routes back to its upstream transits. For those routes where the transit path via AS4877 represented a shorter path, this alternate path was adopted by these transit networks and further promulgated to their routing peers.
We are probably close enough to understand what happened on the 12th June inside AS4788. In the routing primer above we said that as a rule of thumb there are three routing guidelines:
- customer-learned routes are re-distributed to customers, peers, and providers
- peer-learned routes are re-distributed to customers but not to other peers nor to providers
- provider-learned routes are re-distributed to customers, but not to other providers, nor to any peers.
It appears that AS4877 re-advertised peer-learned routes (probably learned from DECIX) to its upstream providers, creating a form of route hijack. This was probably due to a failure in a route policy map in an eBGP router inside AS4877.
Prevention
This form of route leak is not uncommon, and when it happens it can be highly disruptive. Can it be prevented?
RPKI?
These days we hear a lot about the Number Resource Public Key Infrastructure (RPKI) and Route Origination Authorities (ROAs). If the eBGP neighbors of AS4877 had implemented ROA-based filter management would this have prevented the route leak?
The ROAs pin down route origination, and prevent unauthorized AS’s from originating a route to a prefix. In this case, out of the 22,577 leaked routes, it appears that only 1,594 routes involved an origination using AS4877. This implies that, at best, the ROA based route filter mechanism, if implemented by all the route peers of AS4877 and implemented by all prefix holders, would’ve been effective in filtering out just 7% of the leaked routes. The problem here is that what was leaked was transit information, so filters based on origination are largely ineffectual.
If so, then what about if we had AS Path security implemented? What if all the neighbors of AS4877 implemented the complete BGPSEC package and applied validation of the AS Path of all routes received from AS4877. Surely this would detect the problem and reject the leaked routes. Yes?
No.
If you are receiving a route with an AS path of A B C, and the origination at AS C has been verified, then the only way you can identify that this route is an unintentional leak, as compared to the conventional operation of BGP, is not by looking at the operation of protocol per se, but by looking at the routing policy intentions of A, B and C, and working out if what you are seeing with the AS Path is intentional within the scope of the routing policies of these entities. But secure BGP does not contain routing policy information. Secure BGP can allow you to verify that the holder of the prefix authorized C to originate a route, which it is doing. Path security in secure BGP can also allow you to verify that C passed the advertisement to B, who, in turn, passed it to A. So from the perspective of secure BGP there is nothing invalid about this route. BGPSEC cannot inform you whether it is an intentional advertisement of a route or an unauthorized route leak.
So RPKI won't help here. There is nothing ‘incorrect’ with the operation of the BGP routing protocol per se, and there has been no deliberate attempt to falsify routing information. The problem was that otherwise valid routing information was re-advertised to neighbors who did not expect to hear those routes. A customer of a network was re-advertising transit routes, and without some additional knowledge of routing policy concepts such as “transit”, “customer” and “peer”, then the routing system cannot automatically such lapses in the integrity of implied routing policy.
Route Registries?
The use of Internet Routing Registries and the associated Routing Policy Specification Language (RPSL) (RFC 2622, RFC40122) is an alternative approach to the manual management of route filters. RPSL is a relatively rich language and, as the name says, it allows a user to describe a network's import and export policies in terms of relationship with adjacent ASs and its transit (re-advertisement) policies.
If this is used in the context of a routing registry it allows a network operator to enumerate the prefixes originated by the local AS and the transit policies that are associated with these routes. It also allows the network operator to describe its re-advertisement policies by specifying its AS neighbors and the routing policies applied to routes learned from adjacent ASs.
If every AS maintained an accurate, up-to-date and complete set of prefix and route policy entries in an Internet Routing Registry, then it appears that it would be theoretically possible for an AS to generate a prefix and AS path filter set for all of its network adjacencies through a computation across the registry's contents. Indeed there are tools that attempt to do precisely that for the existing route registries.
Why aren't we all doing precisely this? Why aren't we using these route registry tools as part of our standard operating practice?
The story about the use of route registries is a very mixed one.
They have been around for almost twenty years now in one form or another, and some regions of the world have been very diligent in compelling every network operator in their region to maintain accurate information in their local routing registry. But in other cases the route registry story is not so encouraging.
RPSL is a complex language and it can be challenging to accurately describe the intricacy of some routing policies in RPSL. It’s often the case that the registry is populated with "just in case" entries, as well as historic entries, so sorting out what is current routing intention from other extraneous data in the registry is extremely difficult, and to do so with an automated registry scanning tool has proved not to be possible so far. It’s also the case that network operators often use a level of granularity of each eBGP session between adjacent ASes, while RPSL uses a coarser level of granularity of individual ASes. It is therefore more challenging to describe the individual routing policies that apply to each BGP session between the same two ASes, and there is also the question as to whether network operators would be comfortable in publishing such a detailed level of information about their network's routing policies.
The route registries we use today have various models of authenticity and integrity. It's possible in many cases for a registry user to enter routing information for third party prefixes without the authority of the actual prefix holder. Sorting out what is recognizable as authoritative information from what is not authoritative is not helped by a registry data model that typically includes no validation or authority information. There are also many route registries, and its often the case that they contain conflicting information. Which registry should be "preferred" if one wanted to resolve these contradictions in information? Why?
This would be challenging enough, but the problem is further compounded by the observation that in many areas of the Internet operators have eschewed the route registry approach and rely on their own customized tools. So not only is the quality of the information in route registries variable, the coverage of the information in route registries is also variable.
Valley-Free Routing?
Maybe we are trying to be way too clever and using extravagantly complex tools to solve what is in effect a simple problem. The problem that occurred in AS4778 is the re-advertisement of routes learned from peers and transits to other transits.
The routing policy principle that is intended to prevent this form of route leak is a concept called “valley-free routing”.
If a route is passed from a customer network to its transit provider network then this is an “uphill” segment. It the route is passed across a peering connection then this is an “across” segment. And if a route is passed from a transit provider to a customer network this this is a “downhill” segment. A sequence of these route pairs can start with a sequence of uphill segments, then at most one across segment and then a sequence of downhill segments. A valley-free route path cannot include a downhill followed by an uphill.
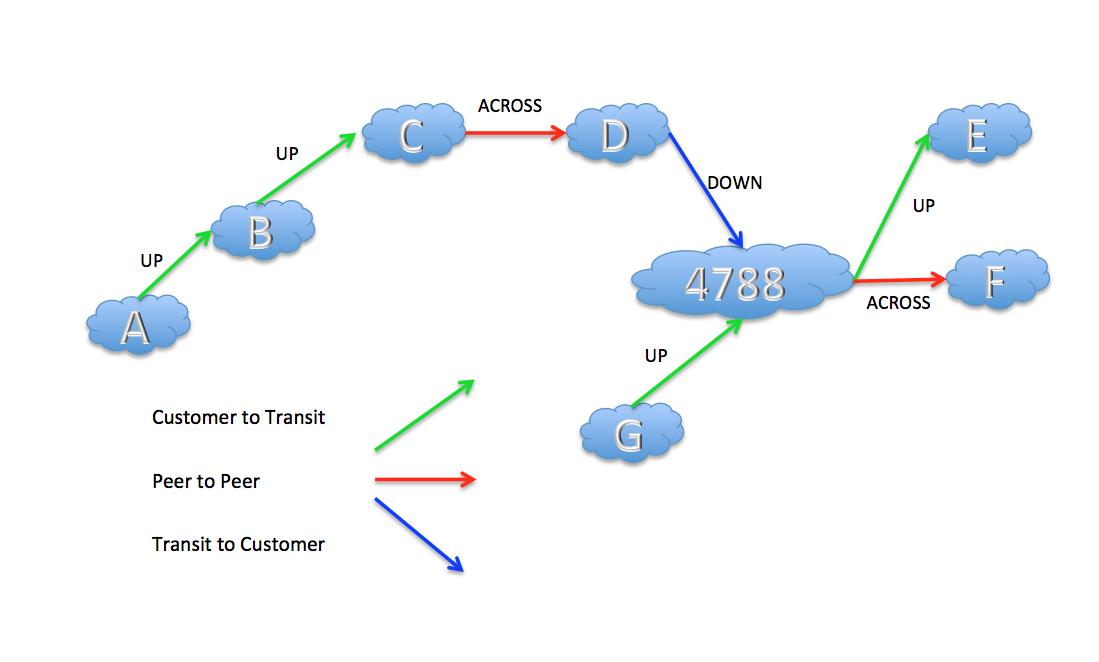
Inter-AS example topology for Valley-Free Routing
In the example shown here a route originated by AS A can be propagated along the path A B C D to AS4788 and satisfy the valley-free constraint. However once received by AS4778 it should not be propagated to either E or F as this would violate the valley-free constraint. A route learned from G can be propagated to D, E and F, according to the same principle. If it is propagated to D, then according to the same valley-free principle, it may be further propagated from D to C, B and A. On the other hand routes learned from E and F can only be propagated by AS4788 to G and not D.
Such a constraint is relatively easy to construct in BGP as a transitive community attribute, called “UP”. When a route is learned with the “UP” attribute then it can be propagated to all eBGP neighbours. However the treatment of the attribute when propagating the route depends on the relationship between the network and its adjacent peer. If the neighbour is a transit provider then the UP attribute is left intact. If it's a peer relationship or a downstream customer relationship then the UP attribute is stripped as the route is passed to the neighbour. If a route is learned without the “UP “ attribute then the route can only be passed to downstream customer neighbours.
While such a mechanism is simple, and undoubtedly could be effective in many scenarios, it is perhaps too simple. While in theory each AS has a uniform routing policy and all AS relationships can be uniformly categorised by the provider/customer or peer relationship, reality tends to be more subtly nuanced, and inter-AS relationships cannot be conveniently shoehorned into this very simple model.
Which is a pity in some respects, as such a simpler world would make routing leak detection and prevention a whole lot easier!
Where to from here?
Some longstanding problems are longstanding because we have not quite managed to apply the appropriate analytical approach to the problem. There is a solution out there, but it involves some searching!
We could try, yet again, to coerce the industry to diligently use route registries for all external routing, but what would be different from this call to use route registries from all the other calls in the past? And if its no different, then why would such a call enjoy any greater levels of take up than has happened in the past?
Maybe we could use digital signatures and the RPKI to combine information authenticity with the route registries. However the issue we may want to consider in this case is would this only make an already complex and difficult system yet more complex and even harder to use?
Maybe this particular problem is a different kind of longstanding problem. Some problems are longstanding problems simply because they are just exceptionally hard problems!
This makes me wonder if there are alternate perspectives on the space we are working in. For example, would we think about this problem differently if we were to think about routing not as a topology and reachability tool, but an distributed algorithm to solve a set of simultaneous equations. The equations here are expressions of routing policies, and the aim of the algorithm is to converge on solutions that solve individual equations as well as converging on a network-wide solution of maximal connectivity. Would such a perspective provide a different insight as to the way in which routing policies and routing protocols interact? And could such a perspective provide some leads as to how we could not only secure the routing system against deliberate abuse and malfeasance but also secure it against inadvertent misadventure in the form of route leaks?
![]()
About the Author
Geoff Huston B.Sc., M.Sc., is the Chief Scientist at APNIC, the Regional Internet Registry serving the Asia Pacific region. He has been closely involved with the development of the Internet for many years, particularly within Australia, where he was responsible for building the Internet within the Australian academic and research sector in the early 1990’s. He is author of a number of Internet-related books, and was a member of the Internet Architecture Board from 1999 until 2005, and served on the Board of Trustees of the Internet Society from 1992 until 2001. He has worked as a an Internet researcher, as a ISP systems architect and a network operator at various times.
Disclaimer
The above views do not necessarily represent the views of the Asia Pacific Network Information Centre.
![]()